Evaluating Search Systems
A data-driven framework for measuring accuracy, relevance, and compliance in information retrieval

Search functionality underpins the user experience of almost every clinical and administrative system in healthcare today. Whether it is a clinician searching a knowledge base for treatment guidelines, a researcher querying a trial registry, or a patient navigating a health portal, the quality of search results directly affects outcomes. Yet most organisations lack a structured approach to evaluating whether their search algorithms are actually working.
This framework provides a systematic approach to search evaluation. By instituting a consistent measurement process, teams can derive meaningful insights into how their algorithm is performing, identify where to focus improvement efforts, and track progress over time.
The Case for Search Evaluation
Search evaluation is not a purely technical exercise. It is a strategic decision with broad implications. For many systems, search is the primary way users engage with the available information. When it underperforms, users get frustrated, miss relevant results, and lose trust in the system. In clinical contexts, a missed result is not just an inconvenience.
A well-tuned search function, on the other hand, can significantly improve how quickly clinicians find what they need, how accurately researchers identify relevant studies, and how effectively patients navigate care options. Evaluation is what makes the difference between guessing and knowing whether your search is doing its job.
Defining Relevance
The fundamental challenge in search evaluation is defining what a good result looks like. This is highly subjective: different users have different intentions for the same query, and the definition of quality varies by context. A relevant result for a clinician searching for drug interactions is different from a relevant result for a patient searching for the same term.
The search community has developed several widely adopted methods for operationalising relevance. No single method captures the full complexity, but combining them gives a reliable picture of performance. These methods operationalise relevance against a ground truth, which is the reference set of known-relevant results used to benchmark the algorithm.
Behavioural Metrics
The most accessible signals come from observing how users interact with search results.
- Clickthrough rate (CTR): The proportion of users who click a result after seeing it. CTR measures attractiveness more than relevance, but it is a useful proxy for whether results are compelling enough to act on.
- Dwell time: How long a user spends on a page after clicking. Low dwell time suggests the result did not satisfy the query.
- Bounce rate: The proportion of users who leave without clicking any result. A high bounce rate indicates the result set was not relevant to the query.
- Task completion rate: The proportion of users who completed a desired action after searching. This is highly context-specific but is the most direct measure of whether search is serving its purpose.
Human-Centred Evaluation
Behavioural metrics tell you what users did, but not why. Human-centred methods add the qualitative dimension.
The simplest approach is direct feedback: a thumbs-up or thumbs-down beside each result. More detailed questionnaires can capture satisfaction and specific aspects of the search experience. For higher-stakes systems, panels of domain experts can rate results against predefined criteria, providing nuanced assessment that automated metrics cannot match. Expert reviewers can evaluate contextual relevance, content quality, and alignment with clinical or regulatory objectives.
Task-based user testing provides insight into what happens when users try to accomplish specific goals using the search. It reveals usability issues and user behaviours that quantitative data alone tends to obscure.
Quantitative Metrics
With a ground truth established, you can measure how well the algorithm retrieves relevant results. The following metrics are standard in information retrieval evaluation and have close counterparts in recommender systems.
Precision and Recall
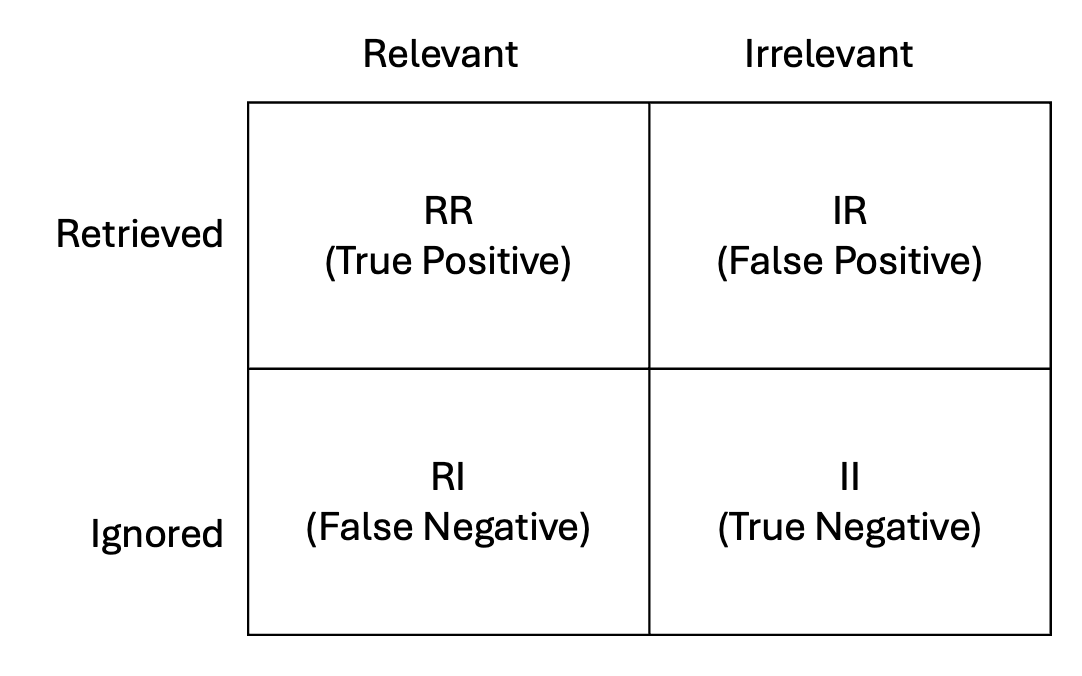
Precision @ K is the proportion of retrieved results (up to position K) that are relevant. Recall is the proportion of relevant results that were retrieved. Both matter: low precision means users see too many irrelevant results; low recall means relevant results are being missed.
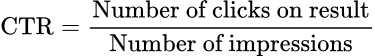
Consider a clinical knowledge base with 8 relevant articles out of 50. The search returns 10 results on the first page, 7 of which are relevant. Precision is 7/10 (70%) and recall is 7/8 (87.5%). The F1-score, the harmonic mean of the two, is 7/9 (78%).
A key limitation of this approach is that it treats all positions equally. A relevant result at position 10 is counted the same as one at position 1, even though users rarely scroll that far. This can be addressed with Mean Average Precision (MAP), which extends precision to account for ranking order.
Score-Based Metrics
Most search indices such as OpenSearch assign relevance scores to results. When these scores are available, classical error metrics can quantify how closely the algorithm matches the ground truth.
Mean Absolute Error (MAE) measures the average difference between the algorithm's assigned scores and the ground truth scores:
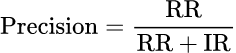
Mean Squared Error (MSE) is similar but penalises large deviations more heavily, making it more sensitive to results that are badly ranked:
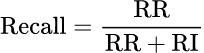
Normalised Discounted Cumulative Gain (NDCG)
NDCG is the most widely used metric for ranking quality. It accounts for both the relevance of results and their position, applying a logarithmic discount so that results lower in the list contribute less to the score. First, the Discounted Cumulative Gain (DCG) is computed:
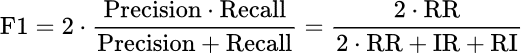
The result is then normalised against the ideal ranking (IDCG) to produce NDCG, a score between 0 and 1 where 1 means the algorithm returned results in the optimal order:
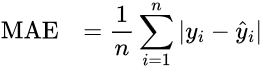
NDCG is particularly useful for healthcare search because it supports graded relevance: a result that is highly relevant to a clinical query is weighted differently from one that is only marginally relevant.
Mean Reciprocal Rank (MRR)
MRR focuses on the rank of the first relevant result. It is the average of the reciprocal rank across a set of queries:
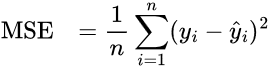
An MRR of 1 means the most relevant result was always returned first. MRR is a good metric for systems where users are typically looking for a single answer, such as a drug interaction checker or a diagnostic code lookup.
Building a Comprehensive Evaluation System
Effective search evaluation combines automated metrics with human judgment. Automated metrics provide scale and consistency; human review provides context and catches issues that numbers miss. Regular expert reviews and structured user feedback sessions should be part of any evaluation programme, not a one-time exercise.
Metrics also need to be calibrated to the specific context. The right evaluation framework for a clinical decision support tool is different from the one for a patient-facing portal. Define success criteria based on the actual goals of the system and the needs of its users, and revisit those criteria as the system and its user base evolve.
In regulated healthcare environments, search evaluation also has a compliance dimension. If a search system is used to surface clinical guidelines or safety information, demonstrating that it reliably returns relevant results is part of the validation evidence required for deployment. A documented evaluation framework, with defined metrics, ground truth datasets, and periodic review cycles, is the foundation of that evidence.