Multi-Cloud Data Governance with Databricks
Federated data access patterns for compliant sharing of patient and clinical data across cloud environments

Many healthcare organisations have data spread across multiple cloud environments. Clinical data may live in Azure Blob Storage, research data in Amazon S3, and operational data in a third platform. Each environment was chosen for good reasons, but the result is data silos that make it difficult to get a unified view for analytics, research, or AI model training. Moving data between clouds is expensive, slow, and introduces compliance risk every time PHI crosses a boundary.
Delta Sharing in Databricks offers a different approach: federated access that lets analysts query data where it lives, without copying it. This article walks through the architecture, the governance controls, and the practical considerations for deploying this pattern in a regulated healthcare environment.
Solution Overview
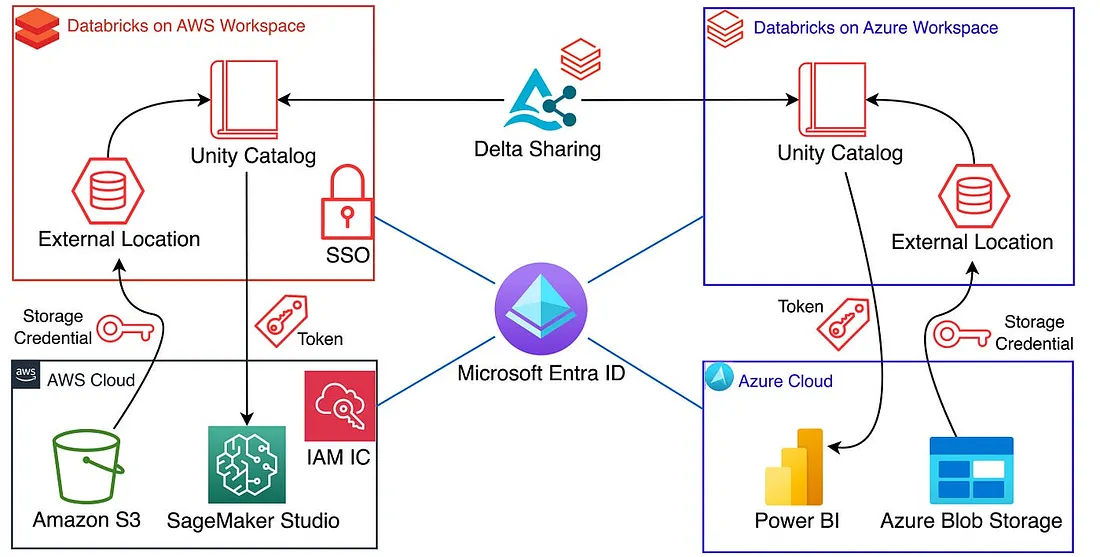
The architecture deploys Databricks workspaces in each cloud environment and uses Delta Sharing to enable secure, cross-cloud data access. The Databricks Unity Catalog acts as the centralised governance layer, providing a single place to manage permissions, lineage, and audit logs across all environments.
A useful analogy: imagine several hospital departments, each with its own records system. Each department has data that other departments sometimes need. Traditionally, getting that data means requesting an extract, waiting for it to be sent, and loading it into your own system. With a federated approach, each department publishes a catalogue of what it has, and authorised users from other departments can query it directly without the data ever leaving its source system. Delta Sharing is the federated catalogue layer; the cloud environments are the departments.
This eliminates complex data migration and replication processes, reduces latency, and ensures analyses are always run against current data rather than a stale copy.
Cross-Cloud Data Access
Enabling Delta Sharing involves configuring the appropriate settings in each Databricks workspace. Once enabled, the catalogue owner of a provider workspace grants access to specific datasets. This can be done through the Databricks portal or programmatically via the REST API or CLI.
In the recipient workspace, shared datasets appear as external tables. Analysts can run standard SQL queries or use Databricks notebooks against them exactly as they would with local data. There is no data migration, no replication pipeline to maintain, and no delay between when data is updated at the source and when it is available to query.
Delta Sharing also supports secure sharing of notebooks and models across workspaces, enabling collaboration on analytics assets without duplicating effort or passing datasets around manually.
Integrating with Cloud-Native Services
The federated data layer integrates with cloud-native services in each environment, allowing organisations to use the best tools from each cloud without being locked into one.
- Amazon SageMaker AI: ML services can authenticate to Databricks using OAuth tokens or personal access tokens and access data through the Unity Catalog for model training at scale. The Databricks extension for VS Code makes this seamless in the SageMaker Code Editor.
- AWS Glue catalog federation: Allows existing AWS Glue catalogs to be integrated with the Unity Catalog without manually migrating metadata, providing a single pane of glass for all dispersed data assets.
- Microsoft Power BI: BI tools can connect to the Unity Catalog directly, with authentication via OAuth or SSO, enabling comprehensive dashboards that draw on data from multiple cloud environments.
Security and Governance
In a healthcare context, the governance controls are as important as the data access capabilities. Delta Sharing provides fine-grained permissions so that only authorised users can access specific datasets. Data is encrypted in transit. The Unity Catalog maintains audit logs of all data access, changes, and sharing events.
Identity federation and single sign-on are essential for a multi-cloud environment. Using a centralised identity provider such as Microsoft Entra ID or AWS IAM Identity Center allows users to authenticate once and access Databricks workspaces in both Azure and AWS without maintaining separate credentials for each environment. To configure SSO in Databricks, organisations can create a SAML 2.0 app in Entra ID or another identity provider.
Data governance in a multi-cloud environment requires comprehensive access control policies that define who can access what data and under what conditions. Coupled with data lineage tracking and audit capabilities, these policies support compliance with HIPAA, GDPR, and other regulatory frameworks. Tracking lineage across clouds is challenging because each cloud has its own native lineage tools. Third-party governance platforms such as Immuta can bridge this gap, though they introduce additional cost and complexity.
Continuous monitoring of data access is essential. Audit logs from Databricks should be integrated with a centralised monitoring platform so that anomalies, unauthorised access attempts, and policy violations are detected and escalated promptly. Regular reviews of access control policies ensure they remain aligned with current roles and regulatory requirements.
Cost Considerations
Multi-cloud data architectures introduce several cost factors that need to be managed deliberately. Storage costs, compute costs for data processing, and the cost of Databricks licences all vary with usage and scale. The most significant and often underestimated cost is data transfer between clouds.
When data is transferred between cloud providers, it travels over the public internet rather than within a cloud provider's internal network. This incurs egress charges from the source cloud and adds latency that depends on the geographic distance between the availability zones involved. For large datasets or high-frequency queries, this can become a material cost.
Strategies to manage costs include right-sizing warehouse instances, using reserved or spot instances where workloads allow, implementing data compression and partitioning to minimise the volume of data scanned per query, and using cost monitoring tools such as AWS Cost Explorer, Microsoft Cost Management, and the Databricks billing portal to track spending patterns. Third-party FinOps platforms such as Datadog or Apptio can consolidate visibility across clouds, though they add their own cost.
It is also worth noting that serverless compute options stop warehouse instances when not in use, but this is not the same as paying only for queries executed as with Amazon Athena. Understanding the billing model of each service before committing to an architecture avoids unexpected costs at scale.
Conclusion
A federated multi-cloud data architecture using Delta Sharing gives healthcare organisations the ability to break down data silos without the compliance risk and operational overhead of moving data between clouds. Analysts and data scientists can join and transform data across environments using standard tools, governance is centralised in the Unity Catalog, and access controls are enforced consistently regardless of where the data lives.
The pattern comes with real tradeoffs: cross-cloud data transfer costs, latency that depends on network geography, and the complexity of maintaining governance policies across multiple platforms. These are manageable with the right architecture and tooling choices, but they need to be planned for rather than discovered after deployment. For organisations already operating in a multi-cloud environment, this approach offers a practical path to unified data governance without requiring a costly and risky data consolidation project.