Resilient Serverless Messaging for Fault-Tolerant Workflows
Designing fault-tolerant retry mechanisms for stateless healthcare data processing workflows
Healthcare data pipelines are rarely simple. A clinical event such as a lab result, a medication order, or a device reading often needs to flow through multiple downstream systems: an EHR, a notification service, a regulatory reporting endpoint, a billing platform. Each of those systems can be temporarily unavailable, throttled, or slow. Without a deliberate retry strategy, transient failures become data loss, and data loss in a clinical context can have real patient safety consequences.
Serverless queue processors are a common pattern for this kind of event-driven healthcare integration. They pull messages from a queue, process them, and push results to downstream services. But when a downstream system is unavailable, the default retry behaviour of immediate re-attempts with a fixed backoff can overwhelm a recovering service and make the outage worse. This post proposes a custom retry mechanism that gives you fine-grained control over retry timing without requiring a stateful workflow orchestrator.
Solution Overview
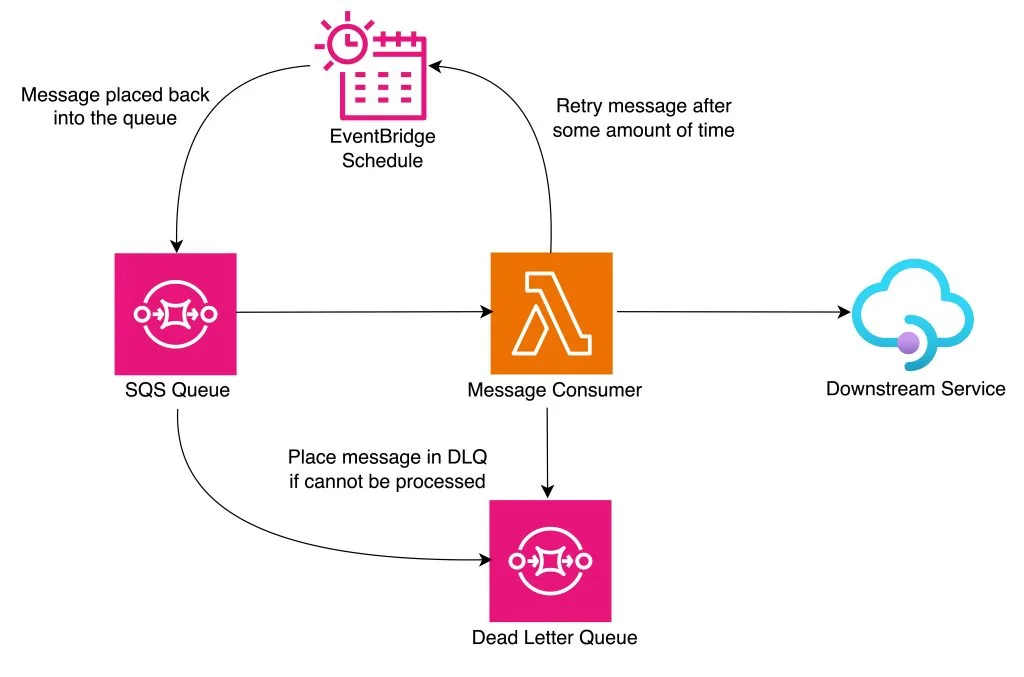
The core idea is to use a scheduled event service as a delay mechanism. When a serverless function fails to deliver a message to a downstream system, instead of immediately re-queuing it, the function creates a scheduled event for a future time. That scheduled event places the message back onto the source queue at the right moment, ready for the next processing attempt. This separates retry scheduling from message processing, keeping the function itself stateless and focused.
The retry mechanism supports configurable timing strategies: exponential backoff, linear intervals, or custom schemes based on error type. For example, a transient EHR throttle might warrant a short backoff, while a downstream system undergoing maintenance might warrant a longer one. The delay can be calculated dynamically in the function based on the error type and the number of prior attempts.
Retry tracking uses message attributes for idempotency. On each attempt, the function appends a timestamp to a retry history array in the message body. If the number of attempts exceeds the configured maximum, the message is routed to a dead-letter queue (DLQ) rather than rescheduled. This prevents a persistently failing message from cycling indefinitely through the pipeline.
The DLQ is a critical component in regulated healthcare environments. Messages that exhaust their retries, whether due to a data quality issue, a schema mismatch, or a persistent downstream failure, are held for manual review, reprocessing, or escalation. This supports the audit and traceability requirements common to HIPAA-covered workflows and GxP-regulated data pipelines.
Considerations and Best Practices
Partial failures deserve special attention in healthcare integrations. If a function completes some steps but fails before finishing, for example writing to the EHR but failing before updating the notification service, a naive retry will re-execute the entire message, potentially creating duplicate records. Compensating actions or idempotency keys at each downstream call are essential to maintain data consistency.
Retry limits need to be set with clinical context in mind. A lab result that fails to reach a clinician after five attempts is a different risk profile than a billing event that fails after five attempts. We recommend defining retry limits per message type, factoring in the clinical urgency of the data, the SLA of the downstream system, and the cost of over-retrying a recovering service.
The scheduled event service used for delay has a minimum granularity of one minute, and there is additional latency introduced by queue polling. This means the mechanism is not suitable for sub-minute retry requirements. For time-critical clinical events such as real-time alert delivery, a different pattern like synchronous retry with circuit breaking is more appropriate. This pattern is best suited to asynchronous, non-urgent data flows like batch lab result delivery, administrative event processing, or regulatory reporting.
Scaling behaviour should be monitored carefully. High-volume clinical event streams can generate large numbers of scheduled retry events during a downstream outage. Function concurrency limits and queue retention periods should be tuned to prevent a backlog from overwhelming the system when the downstream service recovers.
Security is non-negotiable in healthcare data pipelines. If downstream services run inside a private network, the processing function should be deployed into the same network boundary, with the scheduler accessed through a private endpoint. Access controls should follow the principle of least privilege: the function needs permission to create scheduled events and write to the DLQ; the scheduler needs permission to write to the source queue; nothing more.
Monitoring and Troubleshooting
Effective monitoring of this pattern requires visibility at three levels: the queue, the function, and the DLQ. Queue depth and age-of-oldest-message indicate whether the pipeline is keeping up with incoming events. Function error rates and duration metrics reveal processing problems. DLQ depth is the most important clinical signal. A growing DLQ means messages are failing persistently and require human attention.
Set up alerting on DLQ depth with thresholds appropriate to the clinical context. A single message in a DLQ for a critical lab result pipeline warrants immediate investigation; a handful of messages in a low-priority administrative pipeline might be acceptable to review in the next business day.
Structured logging in the processing function is essential for traceability. Log the message ID, retry attempt number, error type, and downstream system on every invocation. This makes it straightforward to reconstruct the history of a specific clinical event, which is a requirement for incident investigation and regulatory audit.
Future Enhancements
Dynamic retry intervals based on downstream service health are a natural extension of this pattern. Rather than using a fixed backoff scheme, the function could query a health check endpoint or a circuit breaker state store before scheduling the next retry, skipping the delay entirely if the downstream system has already recovered. The tradeoff is additional complexity in the retry logic itself, which introduces a new failure surface.
Centralised retry configuration stored in a parameter store or configuration database would allow operations teams to adjust retry limits and backoff strategies without redeploying function code. This is particularly useful in healthcare environments where retry policies may need to change in response to downstream system maintenance windows or regulatory guidance.
Advanced error classification and reporting would allow the system to distinguish between transient failures (network timeouts, throttling) and permanent failures (schema validation errors, authorisation rejections), routing each to the appropriate handling path. Permanent failures should go directly to the DLQ without consuming retry budget; transient failures should be retried with backoff.
Conclusion
Reliable message delivery is a foundational requirement for healthcare data pipelines. The pattern described here, serverless queue processing with scheduled retries and a dead-letter queue, provides a practical, cloud-agnostic approach to building fault-tolerant integrations between clinical systems. It gives engineering teams fine-grained control over retry timing, supports exponential backoff and custom backoff schemes, and ensures that persistently failing messages are captured for review rather than silently dropped. The pattern applies broadly to any stateless queue consumer, making it a reusable building block for regulated healthcare architectures.